Introduction
Most text processing systems provide a way to
``include'' parts of one document, or independent fragments,
into another. The methods, however, vary widely. Many systems provide
a ``mail merge'' that can embed small parts repeatedly, or a
raw copy-when-referenced facility like most programming languages, for
pulling in prerequisite files, macro packages, and so on. This is
very useful, for a variety of basic reasons:
- Economy
Avoiding duplication of data that is often re-used, such as
abbreviations or stock phrases.
- Reliability
Ensuring that such duplications stay the same after editing, by ensuring that
there really is only one ``normative'' copy.
- Dynamic update
Always seeing the latest copy of referenced data, even though it
may be getting updated on an entirely different schedule than the
referencing data, or even created on-the-fly (such as a stock quote or
inventory count).
This mechanism has been around since long before
SGML, having been standard equipment in programming
and macro languages for ages. It was also prominent in the pioneering
hypertext and hypermedia systems developed in the late
1960s:
Brown University's Andries van Dam built the
FRESS system, which had extensive facilities for
including remote content and markup by reference; and for controlling
the sub-parts, in terms of re-use, conditional inclusion based on
arbitrarily complex attributes and expressions, and so on.
SRI's Douglas Engelbart built
NLS and Augment, which introduced fine-grained ways
of referring to hierarchical sub-parts of structured documents, and of
maintaining persistent names so that the links and quotations would
survive later editing.
Ted Nelson, however, most clearly saw the potential of dynamic,
on-the-fly inclusion on a world scale, and coined the term
``transclusion'' for it. He focused on the case of
quotation, assuming that there would eventually be a worldwide
collection of accessible information, which people would explore and
link.[1]
[1] At the time, few people believed him.
More recently we have seen it in less dynamic forms; what we now
call ``dynamic document assembly'' is simply a great deal of
transclusion, except that it is typically done either as a batch
process, or by a heavy server assembling things for a client (rather
than being woven right into the thread of every transaction). Much
specialized web-server processing is also faking transclusion (since
HTML didn't contemplate it except for one
case described below). So transclusion is becoming quite widespread;
but only in certain specific guises, and with many unnecesary
constraints. Here we discuss some of the general principles and
processes underlying all these different guises of transclusion, and
how those can be addressed in SGML and
XML systems.
Definitions
Transclusion is the dynamic inclusion of data from one document
in another. In essence this is quotation, but with a wide range of
advantages (and challenges) that arise from making it dynamic and
online.
We call the document which references other data the
``referring document,'' and the place in it where the
reference occurs the ``referring context.'' Technically,
there is no need for any kind of reference to be expressed inline, and
many hypertext systems (including HyTime, TEI,
Microcosm, and XLL) provide ways to specify links
externally; we ignore this distinction here for simplicity.
We call the data, which is referenced, accessed, and then shown
largely as if it has occurred in the referenced context, the
``referenced data.'' The place where it originally occurs is
the ``referenced'' or ``original'' context, which
may or may not bear much resemblance to the referencing
context.
The definition of transclusion is not limited to including
entire documents or to including documents of similar type. In its
original sense, the inclusion is meant to be real-time, and to be able
to accommodate issues of dynamic updates and versioning. It is,
however, crucial to transclusion that the referenced data retain its
identity: the reader can tell that something is a quotation instead of
the work of the referring document's author; and moreover can
readily access the referenced information in its referenced/original
context.
For example, an abbreviation (such as an SGML
entity used to expand an oft-repeated acronym such as
NASA) is not properly a transclusion: it does not
achieve the required level of identity and referenced-context
meaning. In contrast, a quotation element typically does represent a
transclusion if the quotation is done by live reference rather than
data-copying. If done by copying but with an accompanying link to the
referenced context, it is a marginal case of transclusion: the
identity is expressed, but the quote isn't really live; this
renders moot some of the semantic issues, but introduces its own
problems such as undetectable obsolescence of the copy.
In HTML
Until recently, HTML did not contemplate
dynamic inclusion. There was no provision for including anything on
the fly, with one exception: graphics. That is, the behavior of these
two HTML constructs is radically different,
although both are links:
<A HREF="foo.htm">
<IMG SRC="bar.gif">
The A element in HTML has
built-in semantics that include a requirement that the reader actuate
the element's content before the referenced data is
retrieved. Of course a program might choose to access the data in
anticipation as a way of optimizing performance, but logically the link is not followed until the
reader requests it. Therefore, this is not transclusion as we have
defined it.
In contrast, the IMG element is typically retrieved
as soon as it is encountered, with no user intervention. This is
essentially a transclusion, except that there is no (standard) way of
transcluding only a portion of a graphic, or any kind of data other
than a graphic (making the SRC attribute of
IMG point to HTML does not have the
effect one might wish for).
So both transclusion and inclusion exist in
HTML, but that distinction is conflated: referenced
HTML can only be included, whereas images can only
be transcluded, leaving some cases hard to achieve. Since
IMG transfers can be slow, most browsers provide a global
option setting to change IMG's behavior to resemble
that of A; but only globally, rather than on a per-link
or per-link-type basis. This leaves some useful functionality
unachievable, and is one of the reasons the XLL
linking specification adds these particular semantics directly.
HTML's FRAME and
IFRAME elements are another way to achieve transclusion.
These function somewhat like SGML
SUBDOC entities: they are able to include only entire
documents, and they create a separate address space, making it
difficult to link into transcluded content. (See further discussion of
SUBDOC below.)
In SGML
SGML can do parts of transclusion in several
ways. The most obvious is direct entity references, which can be used
to pull in almost any data. However, entities are too powerful in
some ways, and not powerful enough in others:
A referenced SGML portion need not be a whole
element, but might consist of the end of one and the start of another
(or even
foo</P><![ RCDATA [...). There are
quite complex constraints on just where you can break entities in
relation to elements, tags, quoted literals, marked sections of
various kinds, and so on. This can lead to referenced data being
interpreted to contain different tags in its referenced context than
in its original context. One can imagine scenarios that make that
useful, but they are extraordinarily rare, and completely opaque to
most normal users. This is one reason XML rules out
this kind of ``asynchronous'' entity reference.
Entities do not have a standard way of referrring to parts of a
data object. Since SGML does not entirely constrain
the form or meaning of system identifiers, anyone can build such a
mechanism, but SGML does not provide it. This makes
using entities for quotation nonportable. XLL
introduces portable conventions for internal references of this
kind.
Since a referenced entity (at least, an SGML
one) is parsed as part of the referencing context, it can have
long-lasting effects there, and therefore the referencing document
must be re-parsed whenever the referenced data is to be updated. Given
the difficulty of incremental SGML parsing, this
makes truly dynamic transclusion using entities quite
difficult.
A second mechanism SGML provides is the
SUBDOC entity. This has the advantage of being
synchronous, and of isolating the parsing contexts of the referring
and referenced documents (thus an unmatched delimiter in one
doesn't radically modify the other's parse). However, a
SUBDOC entity can only be an entire
SGML document, making quotation again difficult;
promoting sub-elements to function as entire documents is sometimes
easy, but sometimes requires re-coding the SGML to
avoid all inclusion exceptions, #CURRENT attributes,
USEMAPs, and other non-local features. Since
SUBDOC also separates the ID spaces, linking
across the transclusion boundary requires more work.
In the end, the best way to do transclusion with
SGML is to treat it like other semantics of
hypertext: build it as specific applications rather than using
intrinsic SGML features.
In XML
XML rules out most of the constructs that
make it hard to implement transclusion with SGML,
such as asynchronous entities and document portions that can parse
differently depending on where they are referenced. This makes truly
dynamic transclusion processors more feasible. Also,
XLL provides a powerful convention for referring to
subtrees of documents on the fly (based on TEI
extended pointer notation), making it very easy to transclude very
specific document portions as required for
quotation. XLL also provides transclusion semantics
as a specific property that can be set for individual links: a link
can be declared to require on-the-fly retrieval and display, or inline
display on demand, or new-window display on demand, and so on, thus
allowing all the needed combinations of behavior.
Classes of problems
Transclusion introduces a number of problems and design
decisions. Most of them arise from a single characteristic: one piece
of data exists in multiple contexts. In SGML, an
entity referenced from several different contexts has no real
``identity'' or structure apart from each particular
context. If it is referenced once in a normal parsing context, once in
an RCDATA element context, once in an RCDATA
marked section context, once inside an attribute value, and once in a
context where there happen to be five NET-enabling
start-tags still pending, it might parse to totally different element
structures in each case. But in SGML terms this is
not a problem: the entity is defined to have no structure apart from a
given context, and no rule says it must have similar meanings in
different contexts.
The issue with transclusion is that the referenced data's
meaning, structure, and content from its original context must be
maintained in the referencing context; remember that our definition
included maintaining the data object's identity, and making the
original context available on demand. Also, it is clearly not a fair
quotation if the parsing or even content of the quoted material can be
changed to an arbitrary degree, merely by the act of quotation.
Below, we discuss several examples of issues raised by
transclusion. These and, we believe, any problem involving transcluded
data can be considered as various combinations of no more than three
classes of problems: presentational problems, addressing problems, and
modification of the transcluded data.
Styling transcluded data
A simple but pervasive challenge in handling transclusions
involves stylesheets. The ancestors of the transcluded element are
typically quite different in the two contexts.
Why is the ancestry important? Mainly because stylesheet
mechanisms for SGML (though not for low-end word
processors) use inheritance down through ancestors to determine many
formatting characteristics. For example, a P's font
is usually not set on P at all, but inherited from a
distant ancestor such as BOOK. This is also typically
true of the font size for P, except that some kinds of
intervening ancestors change it when present: the text of a
P inside a FOOTNOTE or QUOTE
may be smaller because the FOOTNOTE or QUOTE
sets the smaller size, which is then inherited.
Typical style inheritance
Under the hood, what goes on is commonly that the formatter
calculates fonts, geometry, colors, and linking semantics for each
ancestor in turn, working down from the root element to the element
being formatted. As each ancestor's specification is calculated,
it becomes the ``basis'' for the next one down: most or all
properties get re-applied to the next descendant, unless
overridden. This is not a process specific to SGML
applications; Brian Reid's Scribe system included it from the
beginning.[2] Others also described similar algorithms.[3] But what happens when there are two sets of ancestors? Authors frequently
transclude a paragraph that was not (in its originating context)
buried within a FOOTNOTE or other special construct, to a
referencing context where it is so
buried. Which context wins?
[2] For retrospective information about Scribe see ``A
high-level approach to computer document formatting,'' in the
Conference Record of the Seventh Annual ACM Symposium on
Principles of Programming Languages, January, 1980. In addition,
Reid's dissertation is an absolute must-read: Scribe: A
Document Specification Language and its Compiler, Ph.D. thesis,
Carnegie-Mellon University, Pittsburgh, PA. Available as Technical
Report CMU-CS-81-100.
[3] For example, John B. Smith and Stephen F. Weiss,
``Formatting Texts Accessed Randomly,'' in
Software - Practice and Experience (SPE) 17(1),
1987.
For example, consider this transclusion:
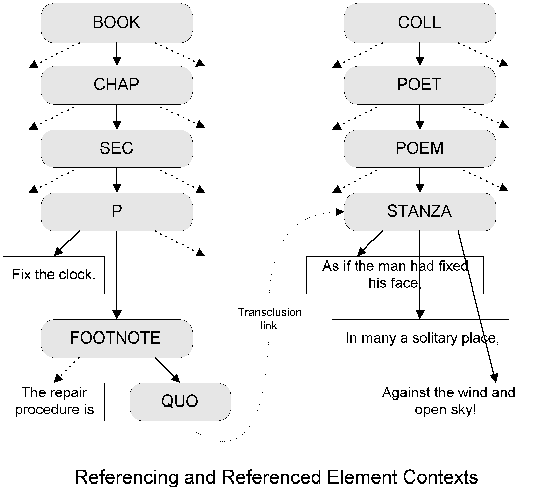
In the referenced context, the STANZA has a
FQGI (fully-qualified generic identifier, or the
list of element type names for all its ancestors in order) of
COLL/POET/POEM/STANZA. In the referencing context that
STANZA ends up with quite a different
FQGI: perhaps
BOOK/CHAP/SEC/P/FOOTNOTE/QUO/STANZA (though see below for
more details on this). Any such difference may lead to formatting
differences, given typical state-of-the-art style mechanisms.
How should it work?
To calculate the ``right'' font and other layout
parameters, we must decide how to relate the two contexts and use each
to contribute to the appropriate style. From the reader's point
of view several requirements must be met in the referencing display
context, even though they may not always fit well together. Formatting
that indicates logical qualities of the referenced data must be
accurate for the referenced context, but the formatting must reflect
the referenced data's status as a transcluded object within a
certain context.
Any difference in appearance from the appearance in the
referenced context must not significantly affect the meaning (unless
of course that is referencer's specific intent!). For example,
you might change the font but certainly would not interpret the
content as though it were in another character encoding.
The display must indicate clearly that the information
is transcluded, and not the
referencing author's own work. For example, a quote should not
be run in with no sign, but must be marked by quotation marks, layout
as an indented block, movement to a separate note area, differing
color, or some other conventional distinction.
The display must fit in smoothly with the style of the
referencing document. For example, if one happens to quote a
large-print edition, it would be silly to display it in that same
large size if the referencing context is not also a large-print edition. Although that may
seem a marginal case, the same principle arises every day in another
form: quoting text from a Web page designed with fonts sized for
low-resolution screens, which print out awkwardly big on paper.
For the moment, make the simplifying assumption that an
element's FQGI is the only thing given to a
stylesheet to determine the element's formatting. That is, the
stylesheet can set up layout parameters with knowledge of an
element's ancestry, but no knowledge of its siblings,
attributes, or other information. This is clearly insufficient for
some applications, even ones so simple as auto-numbering; but it will
do for the moment. Given that, the question reduces to ``what is
the effective (or virtual) FQGI of a transcluded
element?'' For the example above, we see at least these
possibilities:
COLL/POET/POEM/STANZA (the referenced context
unchanged)
BOOK/CHAP/SEC/P/FOOTNOTE/QUO (the referencing
context unchanged)
BOOK/CHAP/SEC/P/FOOTNOTE/QUO/COLL/POET/POEM/STANZA
(the contexts end-to-end)
BOOK/CHAP/SEC/P/FOOTNOTE/QUO/STANZA (the
referencing context plus just the referenced element's own type
information but not its ancestry; if the referenced element has its
own descendants, they would continue the pattern)
BOOK/CHAP/SEC/P/FOOTNOTE/COLL/POET/POEM/STANZA (the
contexts end-to-end, but minus the referencing QUO
element)
COLL/POET/POEM/STANZA/BOOK/CHAP/SEC/P/FOOTNOTE/QUO
(the contexts end-to-end, but referenced first, which seems quite
unintuitive)
In general we believe the goals can be best achieved by
combining the two contexts intelligently rather than choosing one or
the other (the first two choices), since otherwise, depending on the
author's intent, something important may be lost.
For example, any formatting associated with STANZA
elements probably should still apply, since the transcluded data,
after all, is one. On the other
hand, the last-stated goal above, meshing formatting with that of the
referencing document, cannot be achieved at all unless at least some
of that document's context is applied.
Other combinations are possible, such as trying to combine
things at a finer granularity, but this leads to many odd cases: any
proposal involving taking some parameters (say, font) from one
context, but others (such as color) from the other seems destined to
become far too complex to explain. It would also share the known
problems of proposals to combine stylesheets on a piecemeal
basis.
On the whole, it seems the best compromise may be the short
combination shown fourth above: calculate the style as usual in the
referencing context, and then allow the referenced data to override it
based on the GI at the root of the transcluded data
(and of course internal ones if any), but not to inherit from the
referenced context outside of the referenced data itself.
Before proceeding, we note that there are some cases where an
extreme solution may be necessary: these are akin to other cases where
formatting is critical for a particular purpose, and the usual
strengths of descriptive markup systems such as
SGML and XML may be overshadowed
by other concerns. First, some documents have format as a part of
their intrinsic meaning, such as concrete poetry where the layout is
indeed part of the poem. Second, certain legal environments may
require absolute format fidelity, such as mandatory warnings in
aircraft manuals, where fine details of icon placement, geometry, font
size, and the like may be regulated. In such settings of course the
designer's options are more limited.
Apart from the issue of having two element contexts, there is a
second issue. Typically, there are two style sheets active: one
applicable to the referencing document, and one to the referenced
document. It may be that the STANZA element has no style
definition in the referencing context's applicable stylesheet,
in which case it seems clear that the referenced context's
should be used (there isn't any other obvious choice). But what
if STANZA is defined in both? A couple of issues
arise:
Does STANZA signify the same concept in both
documents? Two DTDs can easily use the same tag
name for quite different meanings.
Which stylesheet's definition applies? Referencing,
referenced, or some combination?
The first issue, name conflict, is insoluble in principle
without some universal namespace to which local names such as
STANZA can relate. XML is currently
developing such mechanisms by providing syntax to declare a name as
belonging to a particular ``namespace'' defined
elsewhere. An alternative for the transclusion case is to modify the
``foreign'' names somehow, so that referencing
stylesheet's own name usage cannot conflict: if it wants to
affect transcluded STANZA elements, it would have to do
it explicitly, such as by defining a style for
QUO/#TRANSCLUDED#STANZA.
On the second issue, one can hardly ``average'' the
colors, indents, or fonts specified, although some properties could be
combined in a manner akin to Cascading Style Sheets. Assuming it can
be determined that both definitions do refer to the same
STANZA type conceptually, the easiest solution is to say
that the referencing stylesheet wins. This allows local override, and
is analogous to the usual solution for variable-name scoping in other
contexts such as hierarchically scoped programming languages.
Stylesheet control of transclusion interpretation
A general solution for determining the virtual
FQGI like the one above can work for many cases,
but there will still be occasions in which a document designer will
want to control interpretation of transcluded data on a case-by-case
basis.
As one example, an author may transclude the same element into
two locations, expecting two different presentations. One transclusion
may be a cross-reference, and the author may desire that only the
section's title be presented:
<PARA>In <XREF HREF="some.url#CHILD(3,CHAPTER)(2,SECTION)"/>,
the author suggests that pigs can fly.</PARA>
(This is very common in SGML systems.) But on another
occasion, the author may actually desire that the entire section be
presented to his reader:
<PARA>Here, see for yourself:</PARA>
<TRANSCLUDE HREF="some.url#CHILD(3,CHAPTER)(2,SECTION)"/>
Both of these examples are transclusions, since in both
instances the author desires to include an object in another document
as it exists at the time of the reader's access.
Similarly, a list item may be referred to in its original
context, and the author may with the item's original number
preserved (``See step 5.''). At another point, the author
may wish to include that list item in her own list, numbered in the
context of its new home. (These cases and those in the preceding
paragraph are examples of the philosophical ``use
vs. mention'' distinction.)
A stylesheet language designed with transclusion in mind can
give the designer control over the nature of transcluded data's
presentation. For the section reference above, a designer might
specify that XREF elements should display a canonical
object number (such as ``Section 3.2'') followed by the
TITLE child of the transcluded object, and that the text
should serve as a link to that object; whereas TRANSCLUDE
elements should simply display the entire transcluded object.
A stylesheet mechanism like this can also address problems like
those of the STANZA above. Instead of an application
providing a single rule for determining the virtual
FQGI of transcluded data, it might permit the
stylesheet to state what aspects of presentation should come from
which context.
The XREF might be styled as, ``Fetch the
TITLE of the object; style it in the current font; change
the slant; but then use the object's stylesheet for any children
of the TITLE.''
For the TRANSCLUDE, it might say, ``Increase
the margins by three picas and use the current font; reduce the size
by two points; and then use the transcluded object's stylesheet
for any children.''
The STANZA might be handled as, ``Increase the
margins by three picas and use a sans serif font, but otherwise give
the STANZA complete control over its
presentation.''
Addressing and transclusion
Another interesting problem presented by transclusion is
addressing - linking to documents that use transclusion, or even
transcluding parts thereof. Let us consider what happens if a user
selects a range in a document that uses transclusion. Let's take
an example in which the user selects a range beginning outside
transcluded information and ending within the transclusion, and marks
that text for copying or exporting.
Exporting the text of the selection is not an interesting
problem. But what if the selection is to be copied into a hypertext
document?
The first case we consider is that an author makes the selection
in another's document, and pastes the information into her
own. The most likely behavior in this situation is to simply
transclude the selection within the new document; recursive
transclusions are no more complicated than a single one.
If the pasting operation is within a single document,
transclusion would still be an option, but a more likely desired
effect would be to copy the content and markup to the new
location. The information native to the document could be copied
as-is; the transcluded information, if selected in its entirety, could
be referenced from the new location; if the selection is partial, the
transclusion reference can be copied and then modified by the
application, such that the reference now reflects the desired extent
of the target information.
We also consider the special case in which the user has selected
exactly the extent of a transcluded object (modulo some
whitespace). The application's behavior here presents a
potential field for market differentiation. One behavior would be to
dumbly transclude the user's selection, creating a two-level
transclusion. A more intelligent approach would be to recognize that
the selection was composed solely of a transclusion, and create a
transclusion in the new document directly to the original source of
the information. In the latter case, the author might prefer that the
reference actually be to the ``younger'' document; an
application might prompt the user for the intended source of the
information.
Transclusion with modification
A still more interesting case is the modification of transcluded
objects. It is not at all uncommon to wish to edit quoted texts: to
elide unnecessary verbage, or to replace ambiguous pronouns. Since
such modifications will typically be different for every instance of
modified transclusion, we suggest that instructions for modifying the
transcluded information could be contained directly within the
transcluding document.
For instance, DSSSL expression syntax or a
similar syntax might be used:
<PARA>Then, the author ludicrously suggests:
<TRANSCLUDE HREF="some.url#CHILD(3,PARA)">
<REPLACE>
(list (list (node-list-first (children (current-node)))
"[The author]")
(list (node-list-tail (children (current-node))
89)
(string #\[ #\horizontal-ellipsis #\])))
</REPLACE>
</TRANSCLUDE>
</PARA>which would replace the first character with the string
``[The author]'', and everything after a certain point with
``[...]''.
A hypertext language might also supply architectural forms or
known semantics for a simple patching instruction set:
<TRANSCLUDE HREF="some.url#CHILD(3,PARA)">
<REPLACE HREF="some.url#CHILD(3,PARA)STRING(1,'I',0)">
[The author]</REPLACE>
<REPLACE
HREF="some.url#CHILD(3,PARA)STRING(23,'t',0)..DITTO()STRING(-1,'.',0)">
[…]</REPLACE>
</TRANSCLUDE>
which performs the same substitution with
XLL addressing syntax.
[4][4] As of 31 July 1997.
Most modification operations would be covered by a simple set of
three operators: insert, delete, and replace, applicable to elements
or strings therein. A hypertext language would provide the means of
addressing regions to be modified.
Modification of transcluded information opens a variety of
issues in user interfaces. Editing tools can distinguish themselves in
how efficiently they can record the author's modifications. One
particularly interesting area is that of reader modification. If a
reader has permission to edit both
the referring document and the referenced data, and changes
transcluded information, which context should reflect the change? It
is our suggestion that in this ambiguous case, a user interface should
ask the user which was intended, since it seems unlikely that any
general rule could anticipate the user's intention.
Conclusion
We believe that any case of transclusion can be considered by
considering these three aspects (display, addressing, modification)
separately. Market differentiation can occur based on how an
application analyzes a transclusion problem. For instance, if a
modified transclusion is copied to another document, an application
might simply transclude the referenced section; it might copy the
transclusion and modification information; or it might prompt the user
to decide between those two options and the option to modify the
original information again.
Some actions present complications of these aspects. For
instance, out-of-line presentational aspects, such as footnotes, can
pose a challenge to a user interface. Should the footnotes be
presented along with those of the referring document, merged into the
numbering? Should the original document's footnotes be
displayed directly after the transcluded content - and if so,
should they be numbered from 1, or should their original numbers be
used? Should they be included at all?
There is also the thorny issue of information ownership. If
someone is determined to violate the law or simply good taste by
stealing information, there is little way to prevent it. With the
current state of the Web, the pirate can simply copy from a
document's source; unauthorized transclusion can at least let a
curious reader determine the actual source of the information. It is
important that user agents retain the original context of transcluded
objects, so that information about the object can be determined, such
as the ownership declared in metadata associated with the
document's root element, cataloging information, and associated
alternative stylesheets.
Financial issues must also be considered carefully. First, if
transcluded information is only available to paying customers, a user
agent should prompt the user before fetching it. (One would hope that
a user agent would prompt before initiating any financial
transaction.) And what if the transcluded information is subject to
royalties? The creator of a transclusion would do well to examine the
subject of her links; if her page proves to be popular, she may well
become responsible for large sums to the information's
owner.
In the highly non-static arena of the Web, there is also the
issue of moving targets. It relates closely to ambiguities we
encounter in speech: If someone says ``I want to meet the
President,'' it seems obvious enough what they mean. But in fact
he may mean two things, and we cannot tell which: he may wish to meet
the particular person that held the office when they said it (even if
she is no longer President later), or, instead, whoever happens to
hold the office when the meeting occurs. In much the same way, a
reference to given data may have different intents, which are hard to
tease apart until something changes later (but then may become quite
important).
We believe that no one solution can be proposed that will handle
all forms of transclusion, but
that there exists an excellent opportunity for user agents to
distinguish themselves, as XLL makes transclusion
an integral part of our Internet lives.